

Künstliche Intelligenz formuliert RNA-Wirkstoffe
Die Wacker Chemie AG und die CordenPharma International GmbH haben gemeinsam mit der Ludwig-Maximilians-Universität München (LMU) und der Humboldt-Universität zu Berlin (HU Berlin) ein Projekt gestartet, um die Entwicklung von RNA-basierten Arzneimitteln zu beschleunigen. Das Ziel sind Formulierungen von Lipid-Nanopartikeln (LNPs), deren ideale Zusammensetzung durch das Training eines Machine-Learning-Algorithmus zukünftig automatisiert identifiziert werden wird.
Ziel des gemeinsamen Projektes von Wacker Chemie AG, CordenPharma International GmbH, der Ludwig-Maximilians-Universität München (LMU) und der Humboldt-Universität zu Berlin (HU Berlin) ist es, eine neue Generation von Lipid-Nanopartikeln (LNPs) zu entwickeln, die ein wesentlicher Bestandteil von RNA-basierten Arzneimitteln sind. Auf Basis dieser Formulierungen soll ein Machine-Learning-Algorithmus trainiert werden, der automatisiert die idealen Bestandteile für neue RNA-Formulierung identifiziert – bislang ein besonders zeit- und kostenintensiver Entwicklungsschritt. Das Projekt, das am 1. April 2023 startet, ist auf drei Jahre angelegt und wird vom Bundeswirtschaftsministerium mit rund 1,4 Mio. Euro gefördert.
Nach dem Erfolg von RNA-basierten COVID-19-Impfstoffen wird Arzneimitteln, die RNA als Wirkstoff enthalten, großes medizinisches Potential zugetraut. Im Fokus der Entwicklung stehen dabei nicht nur Impfstoffe gegen Infektionskrankheiten, sondern auch Therapien gegen Krebs und Erbkrankheiten. Weltweit haben RNA-basierte oder -enthaltende Wirkstoffe einen enormen Auftrieb erhalten. Dabei wird bei verschiedenen Wirkstoffen mit unterschiedlichen Lipid-Nanopartikel-Zusammensetzungen gearbeitet, deren perfekte Formulierung viel Zeit benötigt und damit auch einen bedeutenden Kostenfaktor darstellt.
Die Entwicklungspartner im LNP-AI-Projekt übernehmen unterschiedliche Aufgaben: Wacker liefert mit der Herstellung der RNA-Moleküle das Kernstück der RNA-basierten Arzneimittel. Neben der in der klinischen Anwendung im Vordergrund stehenden Messenger-Ribonukleinsäure (mRNA) stellt das Unternehmen für das Projekt auch andere RNA-Moleküle wie selbstamplifizierende RNAs (saRNA) und zirkuläre RNAs (circRNA) her. Für diese werden eigens neue Herstellprozesse geprüft. „Die RNA-Molekül-Arten haben verschiedene Eigenschaften, eignen sich für unterschiedliche Zwecke und werden unterschiedlich hergestellt“, erklärt Dr. Hagen Richter, Leiter der Nukleinsäureforschung bei Wacker und verantwortlich für die Koordination des Förderprojektes. „SaRNA und mRNA werden derzeit vor allem in der Impfstoffentwicklung eingesetzt. CircRNAs zeichnen sich durch eine höhere Stabilität aus und eignen sich damit vor allem für Therapien, bei denen Wirkstoffe langsamer und länger freigesetzt werden müssen.“
CordenPharma wird im Projekt gemeinsam mit der HU Berlin Grundbausteine für Nanopartikel, sogenannte modifizierte Lipide, entwickeln. Sie sorgen dafür, dass die Wirkstoffe sicher in den Körper gelangen und am Ziel freigesetzt werden. „Die Entwicklung von Lipid-Nanopartikeln für die RNA-Formulierung ist ein komplexer Prozess, der spezielle Lipide erfordert. Bisher basiert die LNP-Optimierung hauptsächlich auf Screening von funktionellen Lipiden in vielen zeit- und kostenintensiven Experimenten. Machine Learning, welches ein Teilgebiet der künstlichen Intelligenz darstellt, wird dabei helfen, den Zusammenhang von funktionellen Lipiden und effektiven mRNA-Impfstoffen in Zellkulturexperimenten zu verstehen. Dies erlaubt uns, eine neue Generation von Lipiden mit verbesserten Eigenschaften zu entwickeln, die zu noch wirksameren aktiven Inhaltsstoffen führen“, sagt Dr. Adriano Indolese, Global Head of Development & Innovation bei CordenPharma International. Die zelluläre Funktionalität der Formulierungen wird anschließend an der LMU in Zellkulturversuchen untersucht. Hier soll sich zeigen, wie zielgerichtet und gut die Wirkstoffe freigesetzt werden. Mit dem Screening verschiedener RNA-Arten in Verbindung mit den modifizierten Lipiden soll eine möglichst breite Datenbasis entstehen.
Die Daten aus den physikalischen, chemischen und biologischen Analysen der LNPs sowie der verschiedenen RNA-Moleküle werden genutzt, um einen Machine-Learning-Algorithmus für RNA-Formulierungen zu trainieren. Beim maschinellen Lernen geht es darum, dass eine künstliche Intelligenz aus Beispielen lernt und diese nach Beendigung der Lernphase verallgemeinern kann. Konkret soll das System, dessen Aufbau an der LMU stattfinden wird, anhand der Eigenschaften der LNPs die passgenaue Zuordnung zu verschiedenen RNA-Molekülen und letztlich Therapieformen leisten. Der Algorithmus soll nach der Lernphase in der Lage sein, beliebigen RNA-Molekülen passende Formulierungsansätze zuzuordnen. Nach dem Training des Systems wird in der letzten Phase des auf drei Jahre angelegten Projekts die Funktionalität des Systems in einer konkreten Anwendung geprüft.
 Illustration NIH.gov
Illustration NIH.gov Qiagen N.V.
Qiagen N.V.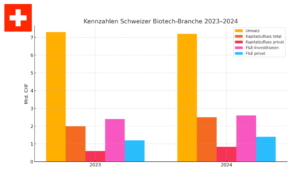 Biocom Interrelations GmbH
Biocom Interrelations GmbH